Amazon S3
- Amazon S3는 AWS의 주요 서비스 중 하나로, "무한대로 확장 가능한" 스토리지 서비스로 알려져있음
- 많은 웹사이트와 AWS 서비스들이 백업 및 저장소로 사용하며, S3를 연동해 다양한 서비스를 제공
- Amazon S3 사용 사례
- 백업 및 스토리지
- 재해 복구
- 아카이브 (기록 보관용)
- 하이브리드 클라우드 스토리지
- 애플리케이션 및 미디어 호스팅
- 데이터 레이크와 빅데이터 분석
- 소프트웨어 제공 및 정적 웹사이트 호스팅


S3 버킷(Buckets)

- S3 버킷은 객체(파일)를 저장하는 공간
- 최상위 디렉토리 개념
- 전역적으로 고유한 이름을 가져야 하며, 특정 리전에서 정의됨
- AWS 상에서 전역적으로 고유한 유일한 속성
- 버킷은 리전 단위로 생성됨
- Naming convention
- 버킷 이름에는 대문자와 언더바를 포함할 수 없음
- 3-63 길이로 작성
- IP주소를 이름으로 쓰면 안됨
- 이름 규칙에는 소문자, 숫자, 그리고 하이픈만 사용해야 함
S3 객체(Objects)

- 객체는 버킷 안에 저장되는 파일로, 각각의 파일은 "키"를 가짐
- Amazon S3 객체 키는 파일의 전체 경로
- s3://my-bucket**/my_file.txt**
- my-bucket : 최상위 디렉토리
- 키 : my_file.txt
- s3://my-bucket**/my_folder1/another_folder/my_file.txt**
- 이 파일을 다른 폴더 안에 위치시킨다면 키 값은 전체 경로가 됨
- 즉 my_folderI/another_foldder/my_file.txt가 키
- 이 파일을 다른 폴더 안에 위치시킨다면 키 값은 전체 경로가 됨
- s3://my-bucket**/my_file.txt**
- 키는 접두사(prefix) + 객체 이름
- IF 위 예제에서 경로를 해체해서 접두사를 분리한다면
- >> prefix : my_folderI/another_folder, 객체 이름 : my_file.txt
- 디렉터리 개념은 존재하지 않음
- 객체는 최대 5TB의 크기를 가질 수 있으며, 5GB 이상의 파일은 멀티파트 업로드 방식을 사용해야 함
- 객체는
- 메타데이터 (키-값 형태)와
- 태그(유니코드 키-값 형태, 최대 10개까지 붙일 수 있음),
- 버전 ID를 포함할 수 있음
👩🏻💻 실습_ S3 👩🏻💻
S3 버킷 생성



- AWS S3 콘솔에 들어가 버킷을 생성하고, 리전 선택 및 고유한 버킷 이름을 설정
- 객체 소유권, 공개 액세스 차단, 버전 관리, 기본 암호화 설정 등을 구성해 보안을 유지
파일 업로드


- 생성한 버킷에 파일을 업로드( coffee.jpg )
- 업로드된 파일은 객체로 저장되며, 객체 속성 및 URL을 확인할 수 있음
- 파일을 열어 확인할 수 있지만, 🚨공용 URL로 접근할 경우 접근이 거부됨🚨.

대신, 미리 서명된 URL을 사용하면 접근이 가능
폴더 생성

- 버킷 내에 "images"라는 폴더를 생성하고, 해당 폴더에 다른 파일( beach.jpg )을 업로드
- 폴더 내에 있는 파일은 버킷 내에서 관리할 수 있음
📌 Amazon S3 – Security
- 사용자 기반 보안
- 사용자 단위로 IAM 정책을 적용할 수 있음
- IAM 정책을 통해 특정 사용자의 API 호출을 허용
- 자원 기반 보안
- 버킷 정책(Bucket Policies) : S3 콘솔에서 바로 버킷에 권한을 설정하는 것
- 특정 사용자나 특정 계정에 속한 사용자에게 권한을 주는 것
- 객체 및 버킷의 ACL(객체 액세스 제한 목록) 을 통해 자원을 보호할 수 있음
- 버킷 정책(Bucket Policies) : S3 콘솔에서 바로 버킷에 권한을 설정하는 것
- IAM 권한에 접근이 허용되어 있거나
- 자원 정책에 해당 자원 접근이 허용되어 있으면 >> S3객체에 접근 가능
- 명시적 거부 액션이 없다면 IAM 사용자는 허용된 API를 호출해 S3 객체에 접근할 수 있음
- 암호화
- 암호화 키를 이용해 객체를 암호화하여 보안을 강화할 수 있음
📌 S3 버킷 정책
버킷 정책은 JSON 형식으로 작성되며 Resource 등에 대한 허용 및 거부 규칙을 설정

- Resources: buckets and objects
- Effect: 허용 / 거부로 나타냄
- Actions: 허용하거나 거부할 대상 API 명시
- Principal: 정책을 적용할 계정 또는 사용자
- 암호화를 강제하고 다른 계정에도 접근 권한을 줄 수도 있음
😊 Example : Public Access - Use Bucket Policy

버킷 정책을 통해 공개 액세스를 허용할 수 있음. 이를 통해 익명의 웹사이트 방문자도 S3 버킷에 있는 객체에 접근할 수 있음
😊 Example : User Access to S3 – IAM permissions

EC2 인스턴스가 S3 버킷에 접근하려면 IAM 역할을 설정해 인스턴스에 권한을 부여하면 됨
🧐 사례 : 계정 간 접근

다른 AWS 계정에서 S3 버킷에 접근할 수 있도록 하려면 계정 간 액세스를 허용하는 버킷 정책을 설정해야 함
⚙️ 퍼블릭 액세스 차단 설정

- 이 설정은 AWS에서 기업의 데이터 유출을 막기 위해 한 단계 추가로 덧씌운 보호막
- 데이터 유출 방지를 위해 퍼블릭 액세스를 차단하는 설정을 활성화
- S3 버킷 정책으로 퍼블릭 액세스 권한을 명시해도 이 설정이 활성화돼 있으면 버킷은 공개되지 않음!!
- 이를 통해 실수로 공개 권한이 설정된 버킷을 보호할 수 있음
👩🏻💻 실습_ S3 보안 : 버킷 정책 👩🏻💻
퍼블릭 액세스 차단 해제 (버킷 > 권한)


버킷 정책 생성

정책 생성기를 사용하여 정책을 만듦
- 사용자: * (모든 사용자에게 권한 부여)
- 서비스: Amazon S3
- 작업: GetObject (객체 읽기 허용)
- ARN: 버킷의 Amazon Resource Name (버킷 이름 뒤에 슬래시와 *추가)

퍼블릭 객체 테스트

- 객체의 퍼블릭 URL로 접근해 coffee.jpg 파일이 정상적으로 뜨는 것을 확인>> 이제 퍼블릭 URL로 객체에 접근 가능함💡
📌 Amazon S3 – Static Website Hosting
- Amazon S3는 정적 웹사이트를 호스팅 할 수 있으며, 인터넷에서 접근 가능하게 설정할 수 있음
- 웹사이트의 URL은 버킷을 생성하는 리전(Region)에 따라 달라짐 (아래 둘 중)
- http://bucket-name.s3-website**-aws-region**.amazonaws.com
- http://bucket-name.s3-website**.aws-region**.amazonaws.com >> 둘의 차이점은 중간에 **하이픈(-) 또는 마침표(.)**가 사용된다는 점!!!
- 사용자가 S3 버킷에 접근하려면 해당 버킷에 퍼블릭 읽기 권한이 있어야 하며, 그렇지 않으면 403 Forbidden 오류가 발생
- 이 오류는 S3 버킷이 퍼블릭으로 열리지 않았다는 의미
- S3 버킷 정책을 수정하여 퍼블릭 읽기 권한을 부여하여 문제 해결

- S3 버킷의 속성에서 정적 웹사이트 호스팅 옵션을 활성화
- 인덱스 문서로 사용할 파일을 index.html로 설정 (해당 파일은 추후에 업로드)
index.html 파일 업로드


정적 웹사이트 테스트

엔드포인트 URL을 브라우저에 입력하여 index.html 파일에 설정된 페이지 확인 가능
📌 Amazon S3 버전 관리
버전 관리 활성화
- Amazon S3는 버킷 단위에서 버전 관리 기능을 활성화할 수 있음
- 버전 관리가 활성화되면 동일한 키(파일 이름)로 파일을 업로드할 때, 이전 파일을 덮어쓰지 않고 버전을 생성 (예: Version 1, Version 2, Version 3).

- 용자(User)가 동일한 키를 가진 파일을 업로드할 때, 버킷은 각 파일에 버전을 부여
- my-file.docx 파일이 버킷에 업로드되면 처음에는 Version 1, 이후 업로드될 때는 Version 2, 3으로 버전이 기록됨
- 모든 버전은 동일한 경로에 저장되며, 필요에 따라 특정 버전으로 복구 가능
버전 관리의 이점
- 실수로 삭제된 파일을 복구할 수 있음. 삭제된 파일은 삭제 마커만 추가되며, 실제 데이터는 남아 있어 복구가 가능
- 이전 버전으로 롤백할 수 있음. 예를 들어, 잘못된 파일을 업로드했을 때 이전 버전으로 쉽게 되돌릴 수 있음
주의 사항
- 버전 관리 기능을 활성화하기 전에 존재했던 파일은 버전 값이 null로 표시됨
- 버전 관리를 중지해도 이전에 생성된 버전은 삭제되지 않으며 여전히 안전하게 보관됨
👩🏻💻 실습_ S3 버전 관리 👩🏻💻
버전 관리 활성화

파일 업데이트 (index.html)

"I love coffee"에서 "I really love coffee"로 변경하여 다시 업로드

업로드 후, 웹사이트에서 새로고침을 하면 변경된 내용이 정상적으로 표시
버전 관리 확인

- S3 버킷에서 버전 표시 토글을 켜면 파일들의 버전 아이디가 보임
- 첫 번째 버전의 아이디는 null, 두 번째 버전은 새로운 버전 아이디를 가짐
버전 롤백

버전 관리 기능을 이용해 이전 버전으로 롤백 가능
객체 삭제, 삭제 마커


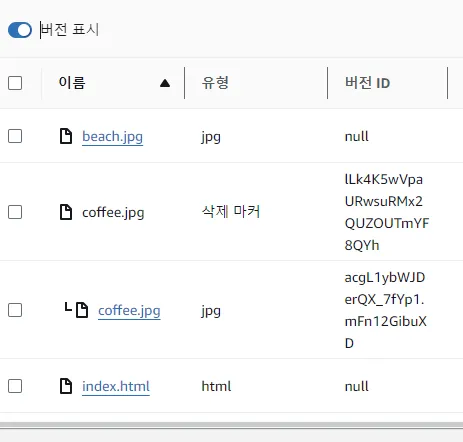
- 객체를 삭제하면 삭제 마커가 붙게 되며, 객체 자체는 삭제되지 않고 삭제 마커에 의해 숨겨짐
- (버전 표시를 비활성화하면 삭제된 파일이 숨겨지고 버전 표시를 활성화 시키면 위 사진처럼 보임)
📌 Amazon S3 복제 (CRR & SRR)
Amazon S3의 복제(Replication) 기능에는 두 가지 주요 유형이 있음!!
한 리전에 S3 버킷이 있고 대상이 되는 버킷은 다른 리전에 있음
>> 이 둘 사이에 비동기 복제를 설정을 원한다면?
>> 소스 버킷과 대상 버킷 양쪽에 버전 관리를 활성화해야 함 !!!
- CRR (Cross-Region Replication)
- 교차 리전 복제는 소스 버킷과 대상 버킷이 다른 리전에 있는 경우 사용됨
- 컴플라이언스 요구 사항 충족, 지연 시간 감소(다른 리전에 있는 데이터를 빠르게 가져옴), 계정 간 복제 등에 적합
- SRR (Same-Region Replication)
- 동일 리전 복제는 소스 버킷과 대상 버킷이 같은 리전에 있는 경우 사용됨
- 로그 집계나 운영 환경과 테스트 환경 간의 실시간 복제에 유용
💡💡💡
- 버전 관리는 소스 버킷과 대상 버킷 모두에서 활성화해야 함.
- 복제는 비동기적으로 진행되며, 이는 백그라운드에서 복제 작업이 수행됨을 의미
- 복제 작업이 정상적으로 이루어지려면, S3에 대해 적절한 IAM 권한을 부여해야 함
사용 사례
- CRR: 규정 준수 목적, 저지연 액세스(다른 리전에 있는 것을 가져오기 때문), 여러 계정 간 데이터 복제 .. 가 좋은 사례
- SRR: 운영 계정과 테스트 계정 간의 실시간 데이터 복제, 로그 집계 등에 쓰임 (운영 환경과 테스트 환경이 별도로 있는 상황에서)
💡복제 참고사항💡
새 객체만 복제
- 복제 기능을 활성화한 이후에 생성된 새로운 객체만 복제됨
기존 객체 복제
- 기존 객체나 복제 실패 객체를 복제하려면 S3 배치 복제(S3 Batch Replication) 기능 (기존에 있던 객체나 복제가 실패한 객체를 복제할 때 사용하는 기능)을 사용해야 함
삭제 작업의 복제
- 삭제 작업도 복제할 수 있는데, 삭제 마커는 소스 버킷에서 대상 버킷으로 복제될 수 있음. (선택사항)
- 버전 아이디가 있는 삭제 작업은 복제되지 않음. 이를 통해 악의적인 삭제로부터 보호됨
복제 체이닝은 지원되지 않음
- 예를 들어, 버킷 1이 버킷 2로 복제되고, 버킷 2가 버킷 3으로 복제될 때, 버킷 1의 객체가 버킷 3으로 자동 복제되지 않음
👩🏻💻 실습_ S3 복제 👩🏻💻
버킷 생성 (버전 관리 활성화 시킨 상태로!)

원본 버킷과 대상 버킷 생성
복제 규칙 생성

- 원본 버킷의 관리 탭에서 복제 규칙을 생성
- 규칙 이름: DemoReplicationRule
- 규칙은 모든 객체를 대상으로 하며, 대상 버킷으로는 s3-hyeonbin-bucket-replica-v2 선택
복제할 때, 기존 객체는 복제하지 않고 새로운 업로드부터 복제되도록 함

복제 테스트


- beach.jpg는 원래 있던 파일이므로 복제 X
- coffee.jpg를 origin 버킷에 추가>> replica 버킷에도 coffee.jpg 복제된 것을 확인 가능
삭제 마커 복제

관리 탭에서 삭제 마커 복제 설정을 활성화


- 원본 버킷에서 객체를 삭제할 때 해당 삭제 마커가 대상 버킷으로 복제됨
(참고로 beach.jpg는 origin에서 다시 업로드해 새로운 버전이 생성됐고, 그것이 복제됨)
📌 S3 Storage Classes
Amazon S3에서 객체를 생성할 때 객체 클래스를 선택할 수 있음
스토리지 클래스는 수동으로 바꾸거나 Amazon S3 수명 주기 설정으로 객체가 자동으로 이 클래스들 중 하나가 되게 할 수 있음
S3 스토리지 클래스
- S3 Standard
- 가용성: 99.99%
- 특징 : 자주 엑세스 하는 데이터 저장. 지연시간이 짧고 throughput은 높음
- 장점 : 두 개의 시설 실패에도 견딜 수 있음.
- 적합한 사용처: 빅데이터 분석, 모바일 및 게임 애플리케이션, 콘텐츠 배포 등.
- S3 Standard-IA (Infrequent Access)
- 가용성: 99.9%
- 특징: 자주 액세스하지 않지만, 필요할 때 빠르게 액세스해야 하는 데이터용.
- 장점: S3 Standard보다 비용이 저렴함.
- 적합한 사용처: 재해 복구, 백업.
- S3 One Zone-IA
- 가용성: 99.5%
- 특징: 한 개의 가용 영역에서 데이터가 저장됨. 그 가용 영역이 파괴되면 데이터 손실이 발생함.
- 적합한 사용처: 온프레미스 데이터나 재생성할 수 있는 데이터의 백업. 재생 가능하거나 덜 중요한 데이터에 적합.
- S3 Glacier:
- 저렴한 객체 스토리지: 아카이브 또는 백업을 위한 스토리지 클래스. 스토리지당 비용과 검색 비용이 발생함.
- 세 가지 종류
- Glacier Instant Retrieval
- 검색 시간: 밀리초.
- 적합한 사용처: 분기당 한 번 정도 액세스하는 데이터. 최소 스토리지 기간은 90일.
- Glacier Flexible Retrieval
- 검색 시간: Expedited (1-5분), Standard (3-5시간), Bulk (5-12시간).
- 적합한 사용처: 대기 시간이 긴 데이터 검색이 허용되는 경우. 최소 스토리지 기간은 90일.
- Glacier Deep Archive
- 검색 시간: Standard (12시간), Bulk (48시간).
- 적합한 사용처: 매우 긴 기간 동안 데이터를 저장해야 할 때. 최소 스토리지 기간은 180일.
- Glacier Instant Retrieval
- S3 Intelligent-Tiering:
- 특징: 액세스 패턴에 따라 객체를 액세스 계층 간 자동으로 이동시킴.
- 비용: 객체 모니터링과 자동 이동을 위한 월별 비용 발생.
- 계층:
- Frequent Access Tier (빈번한 액세스 계층): 기본 티어.
- Infrequent Access Tier (빈번하지 않은 액세스 계층): 30일 동안 액세스하지 않은 객체 대상.
- Archive Instant Access Tier: 90일 동안 액세스하지 않은 객체 대상.
- Archive Access Tier (선택 사항): 90일에서 700일 이상 액세스하지 않은 객체 대상.
- Deep Archive Access Tier (선택 사항): 180일에서 700일 이상 액세스하지 않은 객체 대상.
내구성 및 가용성
- 내구성: Amazon S3가 얼마나 자주 객체를 잃느냐를 의미
- Amazon S3의 내구성은 높음
- 모든 스토리지 클래스가 매우 높은 내구성을 제공하며, 99.999999999% (11 9's)의 내구성.
- Amazon S3의 내구성은 높음
- 가용성: 서비스가 얼마나 사용 가능한지를 의미
- 클래스별로 다름.
- 예를 들어, S3 Standard는 99.99% 가용성을 제공하며, 일부 다른 클래스는 가용성이 조금 낮음.
사용 사례
- S3 Standard는 빈번한 액세스가 필요한 데이터를 위해 설계되었고, 분석, 게임 및 모바일 애플리케이션에 적합함.
- S3 Glacier는 주로 아카이빙 및 백업, 즉시 액세스가 필요하지 않은 장기 데이터 저장에 적합함.
- S3 Intelligent-Tiering은 액세스 빈도에 따라 객체를 자동으로 계층 간 이동시켜 비용 효율성을 높임.
스토리지 클래스 비교
- 각 스토리지 클래스의 내구성은 동일하지만, 가용성은 클래스에 따라 차이가 있음.
- 최소 스토리지 기간 및 검색 비용도 클래스별로 다름.


👩🏻💻 실습_ S3 스토리지 클래스 👩🏻💻
객체 업로드할 때 속성 섹션에서 다양한 스토리지 클래스를 확인


수명 주기 규칙 설정

- 관리 탭에서 수명 주기 규칙을 설정해 객체를 자동으로 다른 스토리지 클래스로 이동하도록 규칙 생성.
- 30일 후: Standard-IA로 이동.
- 60일 후: Intelligent-Tiering으로 이동.
- 180일 후: Glacier Flexible Retrieval로 이동
'AWS' 카테고리의 다른 글
| AWS Section 13. Amazon S3 고급 (0) | 2024.09.27 |
|---|---|
| AWS Section 12. AWS CLI, SDK, IAM 역할 및 정책 (0) | 2024.09.27 |
| AWS Section 10. VPC 기초 (0) | 2024.09.27 |
| AWS Section 9. Route 53 (0) | 2024.09.27 |
| AWS Section 8. RDS+Aurora+ElasticCache (0) | 2024.09.27 |



